


.png)
.png)
.png)
.png)
.png)
Our suite of proprietary technology solutions and methodologies were built “by bankers, for bankers” designed to help customers navigate risk and drive growth. Watchtower provides practitioners, executives and the Board with a panoramic view of risk to make informed decisions and drive performance.
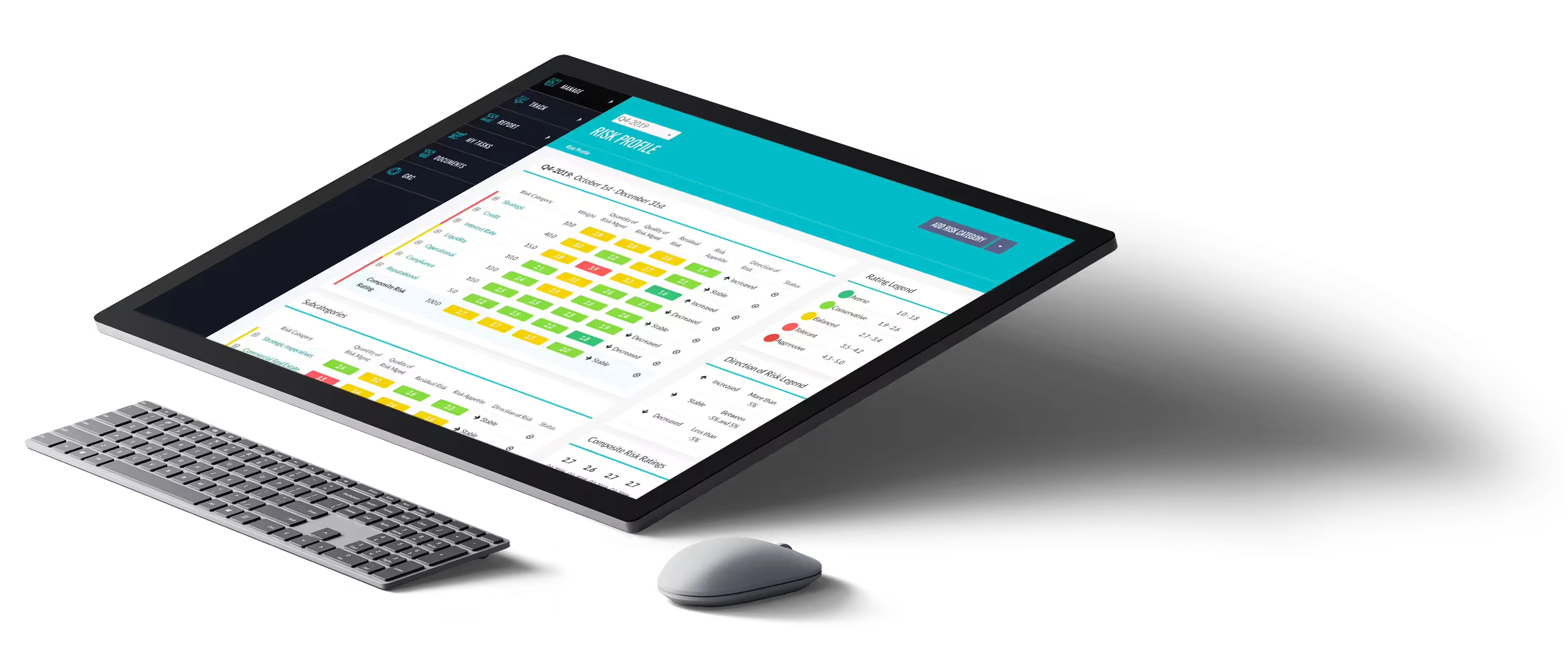
Stop managing risk with manual processes, spreadsheets and presentations. SRA Watchtower closely integrates risk and strategy.

Risk executives are on the line everyday to keep banks and financial institutions safe, sound and ready for growth. They count on SRA Watchtower to see problems before they become too big to solve.
.webp)



























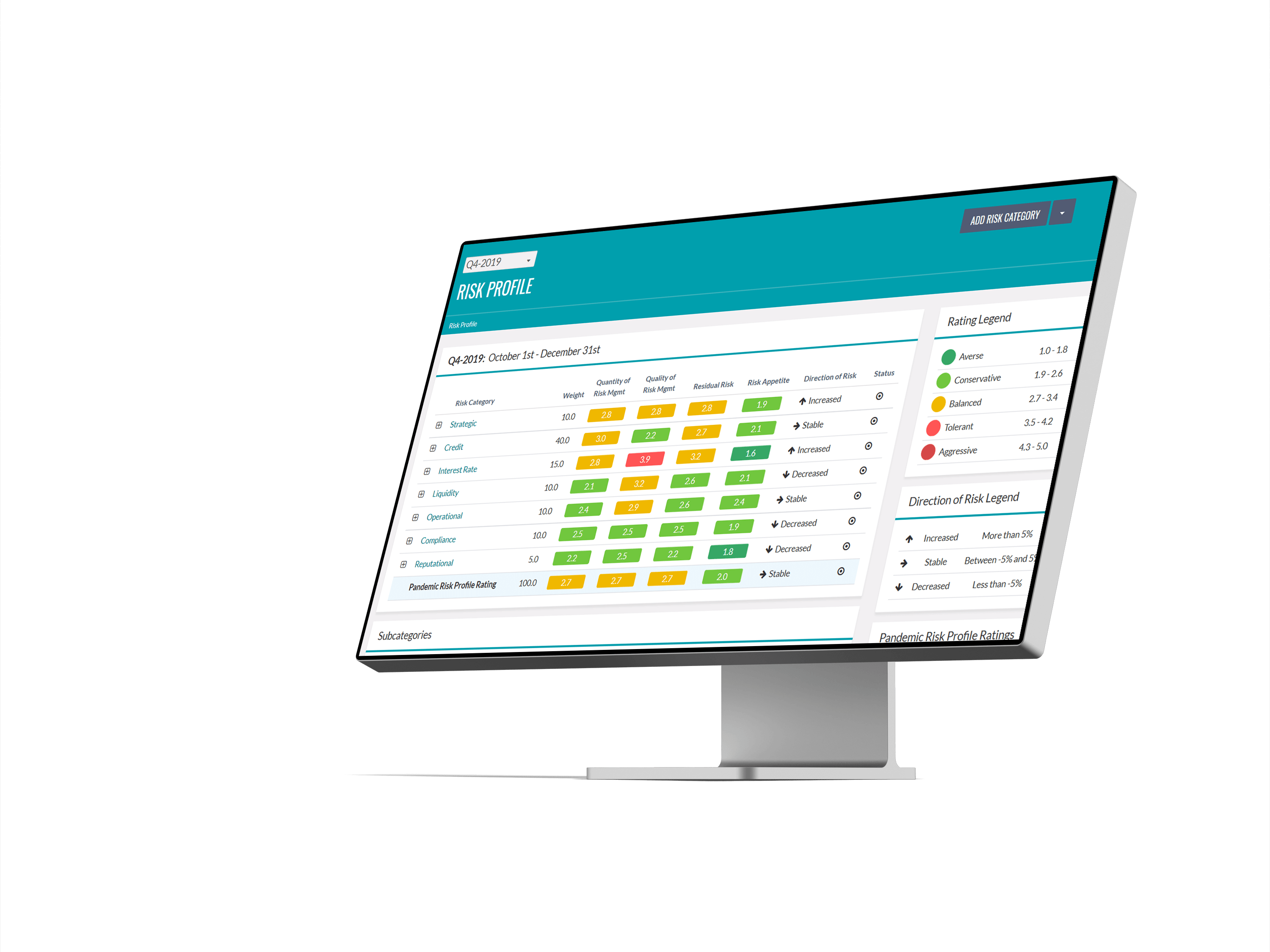
SRAis built to modernize the fulfillment of advanced risk management and strategic imperative performance for financial institutions. We are turning our vision into reality for our clients with state-of-the-art technology, deep experience, and clear and universal language so board of directors and specialized managers have the information they need to take positive action.
SRA’s software is patented and state-of-the-art, built by design for banks. SRA Watchtower seamlessly scales from young DiNovo banks to well-established multinational financial institutions. Our technology faithfully helps our clients fulfill their responsibility to their customers, colleagues, board members and shareholders.
The SRA leaders are hands-on practitioners from national banks, federal government regulators, state bank examiners and credit union executive teams. Our experience in banking, technology, data science, banking law, credit, risk, compliance, governance and finance make us an invaluable problem-solving team.

How well we communicate is determined not by how well we say things, but how well we are understood
How well we communicate is determined not by how well we say things, but how well we are understood
How well we communicate is determined not by how well we say things, but how well we are understood

The ultimate goal of the architect...is to create a paradise. Every house, every product of architecture... should be a fruit of our endeavor to build an earthly paradise for people.

The ultimate goal of the architect...is to create a paradise. Every house, every product of architecture... should be a fruit of our endeavor to build an earthly paradise for people.
The ultimate goal of the architect...is to create a paradise. Every house, every product of architecture... should be a fruit of our endeavor to build an earthly paradise for people.

The ultimate goal of the architect...is to create a paradise. Every house, every product of architecture... should be a fruit of our endeavor to build an earthly paradise for people.
SRA provides technology and advisory solutions exclusively to financial institutions in six critical domains
Board Reporting
Board Training
Governance Framework
Executive Reporting
Profitability
Growth
Planning
M & A
Management
Review & Stress Testing
Process Design
Policy Development
Loan Review
Market, Liquidity & IRR Risk
Capital Management
Capital Planning
Stress Testing
Compliance
Operations
Cyber Security
Legal & Regulatory
Fractional C-Level
Executive Coaching
Risk Training
Recruitment
